Li-Wei’s Blog

Welcome to my Blog! My name is Li-Wei (Weber). I am interested in ML/AI systems and enjoy building things from the ground up, ranging from high performance systems and compilers on single node to distributed systems scaling out across large clusters.
Currently, I work as an ML compiler engineer at Annapurna Labs, making ML models go brrrrrrr.. on Trainium and Inferentia.
ML/AI Systems Projects
Q-learning from Scratch: Implemented the classic Q-learning paper from scratch, including features such as memory replay and weight freezing, achieving convergence on the cartpole problem in 10 training iterations, 200 episodes/training iteration. (https://github.com/lchi021497/q-learning-from-scratch)
Systems Projects (C/C++, Golang)
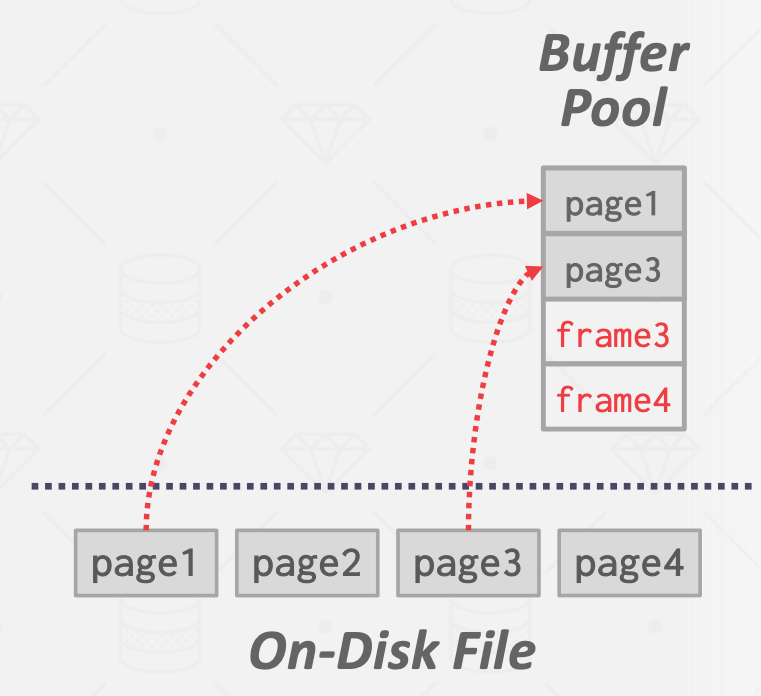
Buffer Pool Manager (Database): Another core component of modern database system is the buffer pool manager that is responsible for the memory management of DB pages in memory. In this project, I implemented a buffer pool manager that swaps in/out DB pages from disk -> memory and memory ->disk, employing the LRU-K eviction policy with respect to the access pattern to the pages, providing a nice API of "page guards" using the RAII design pattern allowing easy management of page read/write locks.
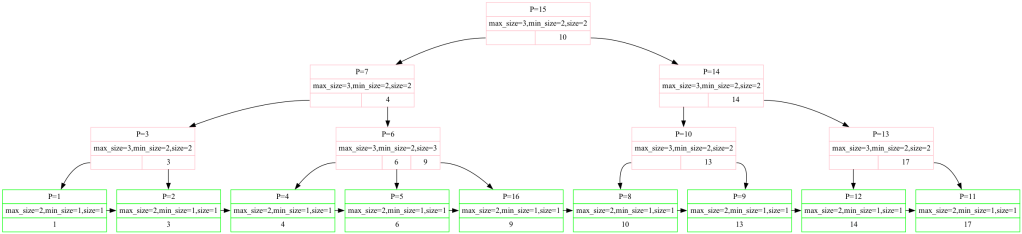
B+ Tree: A common data structure that used in modern databases is the B+-tree data structure. In this project, I implemented a B+ tree index that does insertion, querying, and deletion in O(lg(N)) time complexity from scratch in C++11, supporting concurrent insert/delete operations with crab latching to minimize the lock time and iterator semantics for users to traverse stored items in sorted order

Akka-like distributed key-value store: For geographically distributed key-value stores, an import QoS is latency. A common way of optimizing for latency is to run key-value store clients locally. In this project, I implemented a distributed message-driven system similar to the Akka programming framework (https://akka.io) API with actor semantics.
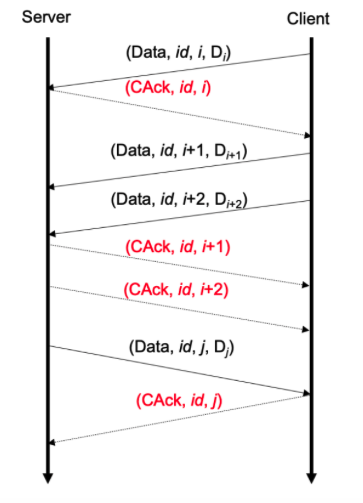
Distributed bitcoin miner: Want to mine bitcoin on hundreds of machines reliably (machine failures? no problem!) In this project, I designed a live sequence protocol that enables bitcoin clients/servers to have reliable communication. The protocol combines UDP and TCP features: able to handle connections with multiple concurrent clients, able to send messages reliably (windowed sequencing), and able to ensure data integrity with CRC16.
Low-level Software

Resource Reservation Framework and Scheduler: Hacked the Linux kernel scheduler to implement a semi-RT linux kernel for real-time applications. Implemented Loadable Kernel Modules(LKM) and sys calls that allow users to reserve time slots that are managed by the kernel. Upon reaching time budget, the kernel context switches process out and sends out signal to running process. The system is able to schedule tasks on the 4-core Nexus 7 tablet using high precision hrtimers to keep track of resource utilization by running processes.

Memory Allocator from Scratch: Created a custom memory allocator with library interposition to intercept calls to malloc() calls. Implemented from APIs of malloc, realloc and calloc, applying data structure optimizations, such as segregated list, footless blocks, and mini blocks, to find the Pareto optimal between throughput and memory utilization.

Memory Allocator from Scratch: Created a custom memory allocator with library interposition to intercept calls to malloc() calls. Implemented from APIs of malloc, realloc and calloc, applying data structure optimizations, such as segregated list, footless blocks, and mini blocks, to find the Pareto optimal between throughput and memory utilization.
High Performance Systems (CUDA, OpenMP)

N-body Simulation: Acceleration on the simulation of N-body gravitational pull on Intel(R) Core(TM) i7-9700 CPU @3.00GHz machine with 8 cores using the OpenMP framework. Achieved ~3x average speed up in building up quad tree data structure and ~8x speed up in simulating n-body movement using the quad tree data structure.

Fast Circle Render: Acceleration on rendering of circles with CUDA C++ on NVIDIA GeForce 2080 GPUs. The problem is broken down into 3 parallelizable steps. 1. The frame is divided into a 64x64 grid, threads are launched with the data of each circle to test for membership in each grid to obtain # of circles - length bit vector for each grid. 2. The bit vector for each grid is compressed using the lg(N) exclusive scan algorithm for each grid. 3. Each pixel renders its color according to the sublist of circles that belong in the grid that the pixel is located in.
